 Time to Open12 weeksSetup window
Time to Open12 weeksSetup windowHow To Open A Disaster Recovery Service In 60–120 Days

Fully Editable
Instant Download
Professional Design
Pre-Built
No Expertise Is Needed
Description

Time to Open12 weeksSetup window  Launch Sequence8 stagesNiche first
Launch Sequence8 stagesNiche first Key BottleneckReadiness gap24/7 coverage
Key BottleneckReadiness gap24/7 coverage First Revenue StepPaid assessmentReadiness review
First Revenue StepPaid assessmentReadiness review


Key Takeaways
- Narrow scope before selling full recovery services.
- Prove restore speed with documented runbooks and tests.
- Match staffing coverage to every SLA promise.
- Validate demand with paid pilots before scaling.
Time to Open12 weeksSetup windowLaunch Sequence8 stagesNiche firstKey BottleneckReadiness gap24/7 coverageFirst Revenue StepPaid assessmentReadiness reviewLaunch timeline
This is a short web summary of the launch plan, and the XLSX export contains the detailed Gantt Chart.
Launch scheduleMonth 1Month 2Month 3Month 4Month 5Month 6Month 7Month 8Month 9Month 10Month 11Month 12
Legal / insurance
- Entity checklist
- Insurance application
- Security review
- Approval follow-up
Vendor / stack
- Hardware shortlist
- Software quotes
- Cloud setup
- Vendor onboarding
- Access hardening
Recovery / testing
- Method design
- Backup validation
- Restore drills
- Proof report
- SLA draft
Staffing / on-call
- Role plan
- Engineer hire
- On-call rota
- Runbook training
- Shift rehearsal
Sales / pilots
- Target account list
- Outbound launch
- Discovery calls
- Pilot onboarding
- Proposal pack
Ops / finance
- Budget baseline
- Cash plan
- Billing setup
- Launch review
- Go-live gate
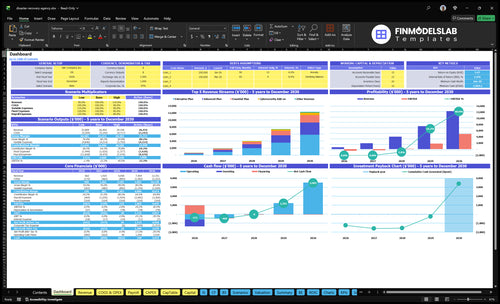
Want to check launch math before go-live?
The screenshot shows revenue, costs, cash needs, assumptions, and break-even logic, so open the Disaster Recovery Service Financial Model Template.
Key launch math to review
- Year 1 marketing: $240k
- CAC implies 100 customers
- Service values: $375-$2,800
- Attach rates: 15%, 8%
- Cloud costs: 18% revenue
- Plan mix, hours, pricing
- Watch runway and staffing
- Track break-even path
What do you need to start a disaster recovery service?
To start a Disaster Recovery Service, you need a minimum viable launch stack: recovery methods, backup and replication tools, cloud recovery access, monitoring, ticketing, documentation, secure remote access, contracts, insurance, service level agreements, technical staff, and a client onboarding process. Start by selling paid assessments, then use What Is The Most Critical Indicator Of Disaster Recovery Service Performance? to explain RTO/RPO targets, since downtime can cost businesses millions of dollars per hour.
Launch stack
- Build tested recovery runbooks
- Set backup and replication tools
- Secure cloud recovery access
- Prepare ticketing and monitoring
Ready to sell
- Price Essential at $150/hour
- Price Advanced at $225/hour
- Price Enterprise at $350/hour
- Review legal and insurance terms
How long does it take to start a disaster recovery business?
For a lean Disaster Recovery Service, expect 60–120 days to launch. The short end works if you start with founder-led assessments and partner tools; the long end fits configured platforms, client security reviews, insurance approval, and 24/7 support planning. The rule is simple: scope first, tools second, runbooks third, SLA design fourth, and restore testing before go-live.
Fastest launch path
- Define service scope first
- Use partner tools early
- Build runbooks before SLAs
- Test restores before launch
Common delays
- Vendor onboarding adds delay
- Cloud setup takes time
- Staffing coverage must be ready
- Security reviews can block go-live
What mistakes make a disaster recovery service risky at launch?
The biggest launch mistakes for a Disaster Recovery Service are selling recovery promises before runbooks are tested, using vague RTO/RPO language, and starting work before scope, access, and insurance are signed off. Risk jumps if onboarding takes too long, client access is incomplete, backup data is unverified, or 24/7 support is implied but not staffed. Do a readiness gap review across contracts, insurance, tool access, test restores, monitoring, staffing, and the Year 1 mix of 45% Essential, 35% Advanced, 20% Enterprise, with cloud infrastructure at 18% of revenue.
Launch risks
- Test runbooks before selling recovery
- Define RTO/RPO in plain English
- Sign scope before any work starts
- Avoid one-vendor recovery paths
Readiness checks
- Confirm client access is complete
- Run test restores on backup data
- Staff real escalation coverage
- Check contracts, insurance, and monitoring
Validate whether the disaster recovery service is ready to sell and ready to recover
Launch readiness checklist
Use this go-live approval checklist before opening to confirm the service can recover client systems and support first incidents.
Governance
- Entity formation completeCritical
Client work needs a legal entity before contracts, insurance, and billing go live.
- Client agreement approvedCritical
Signed scope keeps recovery promises tight and cuts dispute risk.
- Data handling terms reviewedHigh
Data rules must cover access, retention, and incident handling.
- Cyber and E&O boundCritical
Coverage should be active before any client systems are touched.
Service stack
- Service scope definedCritical
A narrow scope stops sales from promising restore work you cannot support.
- RTO/RPO targets setCritical
RTO and RPO set the restore speed and data-loss limits.
- Ticketing and monitoring liveHigh
You need one place to track incidents and system health.
- Secure remote access testedHigh
Remote access has to work before you can help from offsite.
Recovery stack
- Backup and replication testedCritical
A backup that is not restored is just stored data.
- Cloud recovery environment readyCritical
The recovery site must be ready before a real event hits.
- Licensing and partner access confirmedHigh
Missing licenses or partner rights can block a restore.
- Redundancy path validatedHigh
One failed vendor should not stop the recovery run.
Staffing
- Founder on-call role setHigh
Someone must own the first client call after an incident.
- Lead recovery engineer assignedCritical
The restore lead needs technical depth on day one.
- Cloud specialist assignedHigh
Cloud changes and recovery builds need a named owner.
- Escalation chain documentedHigh
Teams move faster when the handoff path is clear.
Sales
- Intake forms readyHigh
Clean intake forms shorten setup and reduce missed details.
- Booking and payment testedCritical
The first sale fails if intake or payment breaks.
- Referral script approvedHigh
Referral partners need a simple pitch they can repeat.
- Backup audit package readyHigh
Audits should be packaged so prospects can buy them fast.
Financials
- Year 1 marketing budget setHigh
Year 1 marketing is budgeted at $240,000, so spend needs discipline.
- CAC target acceptedHigh
CAC starts at $2,400, so lead sources must stay efficient.
- Plan mix model checkedMedium
Mix should start at 45% Essential, 35% Advanced, and 20% Enterprise.
- Cloud cost cap checkedHigh
Cloud infrastructure is modeled at 18% of revenue, so usage needs control.
- Go-live signoff completeCritical
Final signoff should confirm scope, staffing, vendors, and cash through Month 31.
Want to see the six launch drivers that decide readiness?
1Service Scope
60-120 daysA narrow offer speeds pilots and keeps the 45/35/20 plan mix easy to sell.
2Recovery Stack
18% revWorking backup and recovery tools hold cloud infrastructure near 18% of revenue and reduce restore risk.
3Runbooks & SLAs
RTO/RPOTested runbooks turn RTO/RPO promises into proof and make security reviews easier.
4Staffing
8 hrs/clientCoverage and 8 billable hours per client keep response promises credible.
5Trust & Compliance
Signed SLAsSigned SLAs, exclusions, and insurance speed approval with risk-sensitive buyers.
6First Clients
$2.4K CACPaid pilots validate demand before you spend the $240K budget.
Service Scope And Target Market
Narrow DR Scope
If the offer is too broad, launch slips because the team has to pick too many tools, write too many promises, and staff for work it cannot yet deliver. A tighter scope lets the business open with one clear niche, one sales message, and one delivery model, so the first clients see a stable service from day one.
The readiness signal is a clear offer with defined client size, systems covered, response window, and excluded work. Trying to sell full business continuity before proving restore capability is the main bottleneck, because it creates weak onboarding, longer setup, and avoidable delivery gaps.
Set the Offer Before Selling
Before opening, lock the scope in writing and make sure sales, delivery, and support all use the same language. Pick the first lane you can serve well, such as SMBs, MSP referrals, regulated industries, ransomware recovery, cloud failover, backup validation, or business continuity support.
- Define client size.
- List covered systems.
- Set response windows.
- Exclude out-of-scope work.
That keeps pilots faster, onboarding cleaner, and staffing easier to plan. It also cuts the risk of selling a promise the team cannot restore on schedule.
1
Recovery Technology Stack
Recovery Stack Ready
The stack decides whether you can sell, recover, and support clients on day one. For this service, the basics are backup, replication, cloud recovery, endpoint protection, monitoring, ticketing, documentation, secure remote access, and vendor partner setup. If these tools are not integrated, launch delays show up fast in failed restores and weak client trust.
The readiness signal is a test environment with working backup, restore, alerts, access controls, and client reporting. Track vendor cost early: Year 1 cloud infrastructure is modeled at 18% of revenue, easing to 12% by Year 5. Signing clients before the stack is connected creates margin strain and response risk.
Build and Test First
Before opening, confirm every tool is live in the same workflow. Test backup and restore, verify alert routing, document escalation steps, and make sure remote access is locked down. One clean restore test beats a long promise. If a client asks for proof, you need a repeatable report, not a slide deck.
- Test restore on a sample workload.
- Verify alert ownership and timing.
- Lock access controls before onboarding.
- Document vendor contacts and support paths.
- Track cloud cost as a revenue share.
Keep vendor contracts, admin access, and client reporting templates in one place, and assign who owns each system. That cuts launch-day dependency gaps and lowers the chance of taking a first client before the tools are actually connected.
2
Runbooks, SLAs, And Recoverability Proof
Recoverability Proof
Runbooks and SLAs turn a sales promise into a live operating process. For a disaster recovery service, that means defining RTO (how fast systems must come back) and RPO (how much data loss is acceptable), then proving a real restore works inside the promised scope. Without that proof, you can sell backup data that still cannot be restored when a client needs it most.
This matters before opening because downtime can cost businesses millions per hour, so buyers will ask for restore evidence during pilots and security reviews. The launch risk is simple: if the runbook is vague, the team may have storage and copies but no repeatable way to recover fast enough. Documented restore proof is the readiness signal.
Test the first restore
Before launch, lock the acceptance criteria, escalation path, incident message flow, and client signoff step. Test at least one sample workload end to end, and write down what was restored, how long it took, and what fell outside scope. That proof is what lets you open without overpromising.
Keep the first version tight: one customer type, one restore path, one documented handoff. If the restore test fails or takes longer than the SLA, delay the launch rather than sell a promise you cannot meet on day one.
- RTO and RPO
- Test restore results
- Escalation contacts
- Incident communication steps
- Client signoff on scope
3
Staffing And Response Coverage
Staffing And Response Coverage
Coverage has to match the service promise on day one. If the offer implies 24/7 disaster recovery support but the team only has business-hours help, launch risk jumps fast: missed response times, client churn, and weak sales trust. The core plan should spell out who handles the first call, who restores systems, and who escalates when the issue is bigger than one person.
For Year 1, the math is tight. At 8 billable hours per client and $350 per hour, each client implies about $2,800 in delivery time. That makes staffing a launch gate, not just an HR task. If the business sells more clients than the team can cover, onboarding slips and recovery work gets rushed.
Write a coverage plan before the first sale
Build a written plan that lists the founder-operator, recovery engineer, cloud specialist, security partner, and helpdesk or on-call coverage. Define who responds, when they respond, and how incidents escalate. That plan is the readiness signal buyers look for during security reviews and it keeps the launch honest about what can be delivered.
- Map response hours to actual headcount.
- Test escalation before opening.
- Document handoffs and backup coverage.
- Avoid 24/7 promises without real staffing.
What this estimate hides: if coverage is vague, first-client onboarding slows and cash needs rise because you’ll need outside help, overtime, or both. Keep the first scope narrow enough that the team can restore, communicate, and escalate without guesswork.
4
Trust, Insurance, Contracts, And Compliance
Trust, Contracts, And Coverage
For a disaster recovery service, trust work is launch work. Before you can serve clients on day one, you need an entity, a signed client agreement, limitation of liability, cyber liability insurance, and E&O insurance in place, plus clear data handling and security terms. No signed scope, no start.
The launch risk is a client security review that finds weak policies, missing coverage, or vague exclusions. That can delay approvals with regulated or risk-sensitive buyers, even if the tech is ready. A clean package with signed scope, clear SLA terms, documented exclusions, and completed vendor risk answers keeps sales moving and avoids last-minute legal or compliance gaps.
Lock The Paperwork Before Sales
Use qualified legal and insurance professionals before launch. This is readiness, not legal advice. Get the agreement, insurance certificates, and security questionnaire answers done before you book pilots, so the first client review does not stall your opening.
- Confirm entity setup first.
- Document scope and excluded work.
- Set SLA terms in writing.
- Get cyber and E&O coverage.
- Prepare data handling answers.
- Map industry-specific controls early.
5
First Clients, Pilots, And Revenue Validation
First Clients and Pilot Revenue
Opening on time depends on proving the offer with real buyers before you scale spend. For a disaster recovery service, that means paid DR assessments, backup health checks, recovery testing pilots, and a clear path into retainers or managed recovery contracts.
The launch risk is simple: if you buy leads before onboarding and recovery proof work cleanly, you can book sales calls but still miss the day-one service promise. With $2,400 CAC against a $240,000 marketing budget, the plan assumes about 100 customers; that only works if the assessment, report, and close process repeat the same way every time.
Make the first sale process repeatable
Before opening, lock the sales flow into one script, one report format, and one conversion step. The founder should verify the assessment questions, the backup test steps, the recovery proof, and the handoff into a retainer or managed recovery contract.
Here’s the quick check: can you sell, test, report, and close without custom work each time? If not, pause spend. A weak pilot process slows onboarding, creates cash strain, and makes the first 10 customers harder to serve well.
- Use one paid assessment offer
- Test recovery before scaling ads
- Document a fixed report template
- Track conversion to recurring work
6
Related Products
- Disaster Recovery Service Porter's Five Forces Analysis
- Disaster Recovery Service BCG Matrix
- Disaster Recovery Service Business Model Canvas
- 7 Critical KPIs to Track for Disaster Recovery Service
- Disaster Recovery Service Business Plan Template in Pre-Written Word
- 7 Strategies to Increase Disaster Recovery Service Profitability
- Monthly Running Costs for a Disaster Recovery Service Startup
- How Much Does It Cost To Start A Disaster Recovery Service? $420K+ CAPEX
- Disaster Recovery Financial Model Template in Excel
- How Much Disaster Recovery Service Owners Make at 705% Margin
- How to Write a Disaster Recovery Service Business Plan
- Disaster Recovery Service Marketing Mix
- Disaster Recovery Service Marketing Plan
- Disaster Recovery Service Business Proposal
- Disaster Recovery Service PESTEL Analysis
- Disaster Recovery Service Pitch Deck Example Editable PPTX
- Disaster Recovery Service Business SWOT Analysis
- Disaster Recovery Service Value Proposition Canvas
Frequently Asked Questions
Certifications can help, but launch readiness matters more than badges You need tested recovery runbooks, signed service scopes, insurance, vendor access, and clear RTO/RPO language before live recovery work The 60–120 day launch window should include tool setup, test restores, and pilot validation, not just training